
5. UNIT 4. Unsupervised Learning#
This Unit includes main introduction to unsupervised learning, strongly based in [1].
UNIT 4. Unsupervised Learning
EM: Univariate problem
EM: Multivariate case
DBSCAN
Hierarchical clustering
Agglomerative Hierarchical Clustering
Divisive Hierarchical Clustering
PCA with Singular Value Decomposition
5.1. EM: Univariate problem#
from numpy import hstack
from numpy.random import normal
from sklearn.mixture import GaussianMixture
import matplotlib.pyplot as plt
# generate a sample
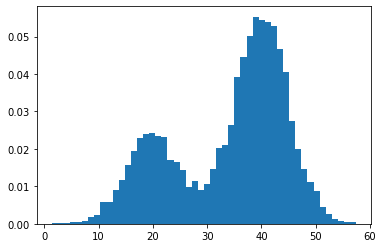
X1 = normal(loc=20, scale=5, size=3000)
X2 = normal(loc=40, scale=5, size=7000)
X = hstack((X1, X2))
# plot the histogram
plt.hist(X, bins=50, density=True)
plt.show()
# reshape into a table with one column
X = X.reshape((len(X), 1))
# fit model
model = GaussianMixture(n_components=2, init_params='random')
model.fit(X)
yhat = model.predict(X) # predict latent values
print(yhat[:100]) # check latent value for first few points
print(yhat[-100:]) # check latent value for last few points
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[0 1 0 1 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0
0 0 0 0 0 1 0 0 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0]
5.2. EM: Multivariate case#
We will code now a step by step example of the ME algorithm.
We will start by retaking the data in the K-Means experiment used in UNIT 2. Now, we are going to use the Expectation-Maximization (EM) algorithm.
In this exercise, we use 300 data points that were independently generated from three bivariate normal distributiuons with means:
cluster |
mean vector |
covariance matrix |
|---|---|---|
1 |
\(\begin{pmatrix}-4\\0\end{pmatrix}\) |
\(\begin{pmatrix}1&1.4\\1.4&1.5\end{pmatrix}\) |
2 |
\(\begin{pmatrix}0.5\\-1\end{pmatrix}\) |
\(\begin{pmatrix}2&-0.95\\-0.95&1\end{pmatrix}\) |
3 |
\(\begin{pmatrix}-1.5\\-3\end{pmatrix}\) |
\(\begin{pmatrix}2&0.1\\0.1&0.1\end{pmatrix}\) |
import numpy as np
from scipy.stats import multivariate_normal
import matplotlib.pyplot as plt
#Xmat = np.genfromtxt('datasets/clusterdata.csv', delimiter=',')
mean = []
cov = []
xmat = []
# define the means and covariances of the three pieces of the dataset
mean.append(np.array([-4, 0]))
cov.append(np.array([[2,1.4],[1.4,1.5]]))
mean.append(np.array([0.5, -1]))
cov.append(np.array([[2,-0.95],[-0.95,1]]))
mean.append(np.array([-1.5, -3]))
cov.append(np.array([[2,0.1],[0.1,0.1]]))
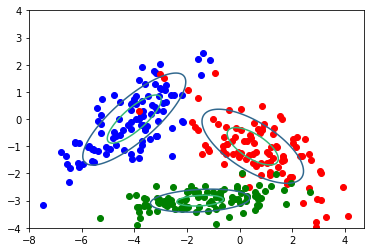
c=['b','r','g']
for i in range(3):
data=np.random.multivariate_normal(mean[i],cov[i],100)
xmat.append(data)
plt.scatter(data[:,0],data[:,1],c=c[i]) # plot each sub dataset
Xmat = np.concatenate((xmat[0],xmat[1],xmat[2]),axis=0)
K = 3 # number of cluster
n, D = Xmat.shape # dimension of data
# plot the contours of the three Gaussians
for i in range(3):
N = 200
X = np.linspace(-8, 4, N)
Y = np.linspace(-4, 4, N)
X, Y = np.meshgrid(X, Y)
pos = np.dstack((X, Y))
rv = multivariate_normal(mean[i], cov[i])
Z = rv.pdf(pos)
plt.contour(X, Y, Z,levels=2)
plt.show
<function matplotlib.pyplot.show(close=None, block=None)>
We will apply the Expectation-Maximization algorithm by introducing auxiliary variables. We use an initial guess of variables \(W\)
The input is the data and an initial guess for the parameters: weights of the Gaussians in the mixture, means and covariances for each
We assign the parameters and evaluate \(\mu\) and \(\mathrm{Cov}\)
We continue iterating until convergence is reached
# convergence is very sensitive to the choce of initial parameters
# so we should try different initial possibilities
W = np.array([[1/3,1/3,1/3]])
M = np.array([[-2.0,-4,0],[-3,1,-1]]) #stores the mu's as columns
C = np.zeros((3,2,2))
# we assume first the covariances in each distribution
C[:,0,0] = 1
C[:,1,1] = 1
p = np.zeros((3,300))
print(p.shape)
for i in range(0,100): # let us iterate a given number of steps
for k in range(0,K): #E-step
mvn = multivariate_normal( M[:,k].T, C[k,:,:] )
p[k,:] = W[0,k]*mvn.pdf(Xmat)
p = p/sum(p,0) #normalize
W = np.mean(p,1).reshape(1,3)
for k in range(0,K):
M[:,k] = (Xmat.T @ p[k,:].T)/sum(p[k,:])
xm = Xmat.T - M[:,k].reshape(2,1)
C[k,:,:] = xm @ (xm*p[k,:]).T/sum(p[k,:])
print(W)
print(M)
print(C)
(3, 300)
[[0.30811885 0.3417826 0.35009855]]
[[-1.54716006 -4.09550252 0.80081707]
[-2.98874145 -0.04513584 -1.31832856]]
[[[ 2.42875572 0.16570491]
[ 0.16570491 0.10175855]]
[[ 1.80454936 1.12889005]
[ 1.12889005 1.23348418]]
[[ 1.94232761 -0.7793724 ]
[-0.7793724 0.96187334]]]
5.3. DBSCAN#
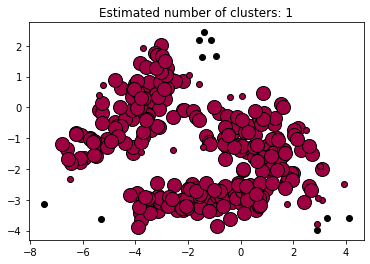
DBSCAN (Density-Based spatial Clustering of Applications with Noise) finds core samples in regions of high density and expands clusters from them. the algorithm works very well for data which contains clusters of similar density.
In the example below we run DBSCAN on the data generated above. In doing so, we realize how data that has not a clear difference in compactness is difficult to clusterize with DBSCAN which, in turn, does a very good job with clearly separated (and grouped) data.
import numpy as np
from sklearn import metrics
from sklearn.cluster import DBSCAN
print(Xmat)
db = DBSCAN(eps=1,min_samples=10).fit(Xmat)
labels = db.labels_
# Number of clusters in labels, ignoring noise if present (noisy samples are given the label math: -1)
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
[[-3.68586805e+00 1.04535095e-01]
[-3.73786659e+00 1.53294597e-01]
[-2.80147624e+00 1.26232239e+00]
[-3.02779398e+00 2.01279903e+00]
[-4.22684541e+00 -2.20732466e-01]
[-5.96418668e+00 -1.63515718e+00]
[-1.10860163e+00 2.17524827e+00]
[-4.01691267e+00 7.46308389e-01]
[-4.53620407e+00 6.28668179e-01]
[-5.38367713e+00 -8.67750023e-02]
[-5.22043277e+00 7.27783868e-01]
[-5.72419971e+00 -9.97901082e-01]
[-2.55420947e+00 -1.37182775e+00]
[-6.48511859e+00 -2.31082994e+00]
[-6.26787507e+00 -8.47241155e-01]
[-4.78859721e+00 -4.82420170e-01]
[-3.11867989e+00 -6.28632331e-01]
[-3.32886311e+00 5.06316292e-01]
[-2.89252952e+00 2.86386198e-01]
[-6.10360832e+00 -1.77866419e+00]
[-4.09961779e+00 -1.48557723e+00]
[-1.38180034e+00 2.43831184e+00]
[-2.61133615e+00 8.85677323e-01]
[-3.80580700e+00 -1.43616612e+00]
[-3.41944309e+00 -7.41444513e-01]
[-3.36693379e+00 1.93503978e-01]
[-3.70220394e+00 6.64567259e-01]
[-3.48622372e+00 8.37020384e-01]
[-5.27247684e+00 -1.67107853e-01]
[-3.64997231e+00 -2.23641294e-01]
[-6.08655477e+00 -8.87343388e-01]
[-3.11237682e+00 -5.92653778e-02]
[-5.27640063e+00 1.49683386e-01]
[-4.11158938e+00 5.62664788e-01]
[-3.74202667e+00 -2.19332892e-01]
[-5.08881050e+00 -1.02107459e+00]
[-3.82704188e+00 1.43941377e+00]
[-3.52607942e+00 -2.43440249e-01]
[-3.26163186e+00 1.77996510e+00]
[-3.82933763e+00 1.14616580e-02]
[-4.14190597e+00 -3.82177862e-01]
[-5.54070564e+00 -1.13317187e+00]
[-5.40411244e+00 4.10260031e-01]
[-4.69202772e+00 -6.07432023e-01]
[-6.59598158e+00 -1.34631280e+00]
[-5.74903223e+00 -1.02716616e+00]
[-6.11826952e+00 -1.63088231e+00]
[-3.20361631e+00 4.27234010e-01]
[-1.48391835e+00 1.62703025e+00]
[-3.59158298e+00 1.30377049e+00]
[-4.40984285e+00 -3.84195663e-01]
[-2.20556394e+00 8.69183187e-01]
[-2.97109026e+00 1.09389282e+00]
[-4.76599970e+00 8.98268009e-01]
[-2.50024081e+00 8.68329097e-01]
[-3.05552387e+00 8.32484836e-01]
[-4.53314536e+00 -6.03529807e-01]
[-4.79032407e+00 -6.80666051e-01]
[-4.11711025e+00 -9.91316551e-02]
[-6.44939861e+00 -1.79386967e+00]
[-4.10873193e+00 -1.27885267e+00]
[-3.57476701e+00 -3.74709388e-01]
[-3.71488032e+00 -9.56248979e-01]
[-3.79133325e+00 -1.13516623e+00]
[-3.18381041e+00 1.71218651e+00]
[-4.12614397e+00 3.49645231e-01]
[-5.36064094e+00 -1.19115428e+00]
[-2.17931309e+00 -7.07475465e-02]
[-6.56142874e+00 -1.66327708e+00]
[-6.78855212e+00 -1.19373327e+00]
[-6.25544548e+00 -8.71717652e-01]
[-3.71381543e+00 1.92877039e+00]
[-5.07119565e+00 -1.29237381e+00]
[-1.59775814e+00 2.19593333e+00]
[-3.93517370e+00 -4.11335301e-03]
[-2.80475980e+00 6.15555547e-01]
[-5.51268948e+00 -1.57954382e+00]
[-2.58598068e+00 -3.27315406e-01]
[-3.12994703e+00 3.50452920e-01]
[-4.57618311e+00 6.21738977e-04]
[-3.72125425e+00 -8.08933202e-01]
[-5.26377962e+00 -5.20548121e-01]
[-2.15628730e+00 -9.40951638e-02]
[-5.56200170e+00 -1.08807957e+00]
[-2.85022369e+00 1.05772794e+00]
[-4.38777227e+00 -1.13984703e+00]
[-3.01705605e+00 1.14465714e+00]
[-3.17312843e+00 -6.07711107e-01]
[-5.59006539e+00 -1.53224203e+00]
[-4.67570377e+00 -9.36124778e-01]
[-3.94743790e+00 5.38657281e-01]
[-5.60775143e+00 -1.11685208e+00]
[-4.91450646e+00 -1.09292510e+00]
[-3.60209618e+00 -4.01888252e-01]
[-3.68100488e+00 3.01080262e-01]
[-2.90390707e+00 6.06573681e-01]
[-3.94324508e+00 8.53216588e-01]
[-7.47631296e+00 -3.14786071e+00]
[-4.07202329e+00 6.02036565e-01]
[-3.21314175e+00 1.29349900e+00]
[ 2.89475743e+00 -3.97598745e+00]
[-1.80956459e+00 -1.13014772e-01]
[-3.00569972e+00 1.65480116e+00]
[-1.30857164e+00 -9.39222551e-01]
[-8.18680354e-01 -1.74268069e-01]
[-2.91200529e-01 -8.00841923e-01]
[ 1.78419798e+00 -2.39625679e+00]
[ 1.02591432e+00 -1.21951712e+00]
[ 2.18236261e+00 -6.73937446e-01]
[ 3.92176221e+00 -2.48206932e+00]
[ 2.40483997e+00 -3.08162482e+00]
[ 3.10708702e+00 -2.99239311e+00]
[ 2.04351104e+00 -7.45602857e-01]
[ 1.39704407e+00 -1.00460377e+00]
[-9.25019686e-01 1.68051589e+00]
[-1.90097235e-01 -6.42761538e-01]
[ 1.64575105e+00 -1.38244384e+00]
[ 1.98509885e+00 -2.13390903e+00]
[ 2.47848814e+00 -7.40193803e-01]
[ 1.93178226e+00 -2.12158877e+00]
[ 1.26974396e+00 -5.42164788e-01]
[-3.80484193e+00 2.91958301e-01]
[-1.19523728e+00 -1.10952718e+00]
[ 1.12378596e+00 -1.28700004e+00]
[ 1.80729911e+00 -2.29497019e+00]
[ 2.90544495e+00 -3.79799026e+00]
[-1.56761739e+00 7.58514613e-01]
[ 4.18883419e-01 -7.09314775e-01]
[ 1.28094965e+00 -1.44927938e+00]
[-4.98004233e-01 -2.77851793e-01]
[ 2.09039099e-02 -1.32617623e+00]
[ 2.38133459e-01 -1.45311882e+00]
[-1.16590290e+00 -1.18694084e+00]
[ 3.48722746e-01 -1.32371513e+00]
[-5.03176541e-01 -1.27463402e+00]
[ 8.56677741e-01 -3.80194142e-01]
[ 3.76996501e-01 -5.94732773e-01]
[-1.45764628e-01 -3.17445291e-01]
[ 3.09004793e+00 -1.99146298e+00]
[ 2.03510166e+00 -8.92813805e-01]
[ 5.03879073e-01 -1.59982619e+00]
[-6.25880389e-01 -9.81134346e-01]
[ 1.15564811e+00 -2.05773712e+00]
[-5.93575370e-01 -6.41185361e-01]
[-7.63015824e-03 -1.38918058e+00]
[-6.03925103e-02 -1.21271510e+00]
[ 3.03700141e+00 -1.89718242e+00]
[ 1.32239940e+00 -3.46085526e-01]
[ 4.07005098e-02 -1.23735053e+00]
[-3.88960747e-01 3.50315226e-01]
[ 1.60345199e+00 -1.52905338e+00]
[ 3.27260061e+00 -3.60457663e+00]
[ 1.19287862e+00 -1.03124930e+00]
[ 1.45912844e+00 -1.76401023e+00]
[-6.22594293e-01 -1.17415302e+00]
[ 1.65979619e+00 -1.36950869e+00]
[ 4.51985728e-02 3.81615301e-01]
[-6.05341988e-01 -1.65942059e+00]
[ 1.70696262e-01 -8.08892501e-01]
[ 5.45946196e-01 -8.80301739e-01]
[ 9.69220501e-02 -2.01698062e+00]
[ 1.02404089e+00 -1.59788456e+00]
[-1.42725131e+00 -1.28886472e+00]
[ 4.10988372e+00 -3.57542309e+00]
[ 1.69995919e+00 -1.49319619e+00]
[-2.44786299e-01 -1.29757621e+00]
[-1.96179291e+00 1.06104283e+00]
[ 4.97968959e-02 -4.09275996e-01]
[ 9.09107067e-01 -1.77972129e-01]
[ 7.05461615e-01 -3.48419096e-01]
[ 7.74429178e-01 -5.24983841e-01]
[-1.02830754e+00 1.84306621e-02]
[ 2.93721086e+00 -2.95193005e+00]
[ 1.15093867e+00 -1.96052631e+00]
[-4.67835474e-01 -9.09631625e-01]
[-1.69288493e+00 -3.01052110e-01]
[ 8.36693832e-01 4.65939180e-01]
[ 1.52012571e+00 1.07327762e-01]
[ 8.00692133e-01 -1.60295563e+00]
[ 8.43301851e-01 -3.85651683e-01]
[ 4.98591145e-01 -1.28355775e+00]
[ 2.38121947e+00 -1.34920842e+00]
[ 1.62338023e+00 -7.11727405e-04]
[-4.60840130e-01 -9.03531077e-01]
[ 3.66536696e-01 -2.50442759e+00]
[ 8.23453899e-01 -2.05345773e+00]
[ 2.31202117e+00 -1.37528295e+00]
[ 1.59534678e+00 -1.99937015e+00]
[-1.56614384e+00 -4.03027292e-01]
[ 6.41544578e-01 -1.72810710e+00]
[ 2.61889783e+00 -2.53847763e+00]
[-2.87850335e+00 1.51485110e+00]
[ 5.40696766e-01 -1.27754071e-01]
[ 1.16340849e+00 -1.56240233e+00]
[ 2.71538843e+00 -1.50564934e+00]
[ 1.42924700e+00 -1.04394011e+00]
[ 6.18426789e-01 -1.22546822e+00]
[ 2.62144300e+00 -1.26742527e+00]
[ 2.15374656e+00 -1.04035301e+00]
[ 2.95570559e-01 -8.13494869e-01]
[-3.49532958e+00 -3.18655975e+00]
[-1.06699262e+00 -3.01961317e+00]
[ 6.76297677e-01 -2.80895945e+00]
[ 5.90279542e-01 -3.33550579e+00]
[-2.19033211e+00 -3.32178804e+00]
[-1.24885437e+00 -2.69518863e+00]
[-3.07167227e-01 -2.85057235e+00]
[-3.81910410e+00 -3.21755138e+00]
[-3.83203750e+00 -3.41829132e+00]
[-3.34021226e-01 -3.05591028e+00]
[ 5.96423009e-03 -3.09606365e+00]
[-1.16812427e+00 -3.08438210e+00]
[ 1.75943515e+00 -3.13584959e+00]
[ 1.38620504e+00 -2.01753984e+00]
[ 9.52444604e-01 -2.64684713e+00]
[-4.12415377e-01 -3.60950861e+00]
[-3.08744911e+00 -3.04521655e+00]
[-3.62322961e+00 -3.20363804e+00]
[-7.58147046e-02 -2.93631229e+00]
[-2.04713575e+00 -2.95597257e+00]
[-5.31327244e+00 -3.63279293e+00]
[-3.14845075e+00 -2.88597782e+00]
[-1.35875874e+00 -2.88410792e+00]
[-1.95473004e+00 -3.22209080e+00]
[-7.20173528e-01 -2.65063886e+00]
[-3.13329221e+00 -3.36942836e+00]
[ 7.14428115e-01 -3.19703579e+00]
[ 1.97046762e+00 -2.36960234e+00]
[-1.65078164e+00 -3.43329038e+00]
[-1.89625256e-01 -2.93754640e+00]
[-1.84196483e+00 -2.47483543e+00]
[-7.36253742e-01 -2.72701525e+00]
[-1.02160953e+00 -3.11663761e+00]
[-1.53820237e+00 -3.22117907e+00]
[-2.00138297e+00 -2.68376234e+00]
[-8.92459911e-01 -2.86097971e+00]
[-3.59017076e+00 -3.12363393e+00]
[-3.78657370e+00 -3.64551386e+00]
[ 8.14664927e-01 -2.91642809e+00]
[-2.62699716e+00 -3.02247194e+00]
[-2.88395948e+00 -3.01169526e+00]
[-3.44680607e+00 -3.42808707e+00]
[ 5.81718138e-02 -2.71209959e+00]
[-2.86113468e+00 -3.12466313e+00]
[ 1.69903609e+00 -2.60098145e+00]
[-2.54756192e+00 -2.50696634e+00]
[-8.83761527e-01 -3.30072527e+00]
[ 7.15606002e-01 -2.93921152e+00]
[-8.24396524e-01 -2.82664001e+00]
[-3.07431459e+00 -3.08104765e+00]
[ 6.51222767e-01 -3.14466728e+00]
[ 9.56571339e-02 -1.99880061e+00]
[-3.94100522e+00 -2.77790366e+00]
[ 7.31634027e-01 -3.16431270e+00]
[-2.01022736e+00 -2.65573686e+00]
[-1.70388152e+00 -2.61618253e+00]
[-2.79149304e+00 -3.15854081e+00]
[-7.41177420e-01 -2.83687439e+00]
[-7.21291138e-01 -2.95795791e+00]
[-6.82127679e-01 -3.19162948e+00]
[-3.07164415e+00 -2.95619897e+00]
[ 5.84401376e-01 -2.67539833e+00]
[-2.43604908e+00 -3.31939016e+00]
[-1.58922326e+00 -2.67846862e+00]
[-5.82701107e-01 -2.56011225e+00]
[-2.26066228e+00 -3.01961565e+00]
[-1.59862442e+00 -2.86295600e+00]
[-3.91226200e+00 -3.89576196e+00]
[ 2.92926640e-01 -2.82578973e+00]
[ 1.20619760e-01 -3.44210900e+00]
[-1.55159413e+00 -2.81344546e+00]
[ 2.97732498e-01 -2.86248529e+00]
[-2.06722498e+00 -2.97233960e+00]
[-2.71074644e+00 -2.91779688e+00]
[-3.54229275e+00 -2.94056047e+00]
[-1.93609885e+00 -2.64763855e+00]
[-7.71517422e-01 -2.70377784e+00]
[-2.03618234e+00 -3.25550744e+00]
[-9.57487826e-02 -2.44963599e+00]
[-2.55033429e+00 -3.13242171e+00]
[-4.21188673e+00 -2.84026109e+00]
[-2.75069990e+00 -3.19155565e+00]
[-2.21483104e+00 -3.25315261e+00]
[-1.70254326e+00 -2.71040554e+00]
[-1.31020115e+00 -2.45019376e+00]
[-1.21822260e+00 -3.36886732e+00]
[-1.01220943e+00 -2.67335600e+00]
[-3.88310451e+00 -3.21819468e+00]
[ 7.36989132e-01 -2.44029573e+00]
[-3.64932926e+00 -2.89417168e+00]
[ 2.27431402e-01 -3.00696089e+00]
[-8.15598529e-02 -2.52634105e+00]
[-2.09160684e+00 -3.21427148e+00]
[-9.07571236e-01 -3.85777781e+00]
[ 2.67204608e+00 -2.67903952e+00]
[-2.61314978e+00 -2.98057194e+00]
[ 2.05043758e-01 -2.54379381e+00]
[ 1.18266751e+00 -2.45147761e+00]
[-3.16351495e+00 -2.44421384e+00]
[ 5.74934004e-01 -2.82250250e+00]]
Estimated number of clusters: 1
Estimated number of noise points: 10
unique_labels = set(labels)
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = labels == k
xy = Xmat[class_member_mask & core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=14,
)
xy = Xmat[class_member_mask & ~core_samples_mask]
plt.plot(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=6,
)
plt.title(f"Estimated number of clusters: {n_clusters_}")
plt.show()
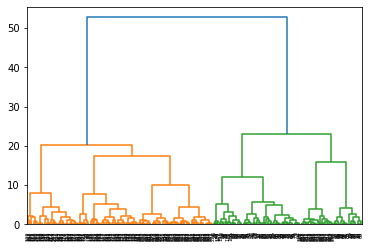
5.4. Hierarchical clustering#
In hierarchical clustering we use either an agglomerative or divisive algorithm to generate clusters in a given dataset. In this very simple implementation, we use scipy to clusterize a collection of 3 clusters and one single orphan data point. Adapted from this entry in Stackoverflow.
The threshold given as a parameter in the code (thresh) is a distance value on which basis the decision is made whether points/clusters will be merged into another cluster. The distance metric being used can also be specified.
import matplotlib.pyplot as plt
import numpy
import scipy.cluster.hierarchy as hcluster
# generate 3 clusters of each around 100 points and one orphan point
N=100
data = numpy.random.randn(3*N,2)
data[:N] += 5
data[-N:] += 10
data[-1:] -= 20
# clustering
thresh = 1.5
clusters = hcluster.fclusterdata(data, thresh, criterion="distance")
# plotting
plt.scatter(*numpy.transpose(data), c=clusters)
plt.axis("equal")
title = "threshold: %f, number of clusters: %d" % (thresh, len(set(clusters)))
plt.title(title)
plt.show()

5.4.1. Agglomerative Hierarchical Clustering#
Find below a basic implementation of the Ward linkage function for agglomerative hierarchical clustering, using scipy functions. Adapted from [1]
import numpy as np
from scipy.spatial.distance import cdist
def update_distances(D,i,j, sizes): # calculate distances for merged cluster
n = D.shape[0]
d = np.inf * np.ones(n+1)
for k in range(n): # Update distances
d[k] = ((sizes[i]+sizes[k])*D[i,k] +
(sizes[j]+sizes[k])*D[j,k] -
sizes[k]*D[i,j])/(sizes[i] + sizes[j] + sizes[k])
infs = np.inf * np.ones(n) # array of infinity
D[i,:],D[:,i],D[j,:],D[:,j] = infs,infs,infs,infs # deactivate
new_D = np.inf * np.ones((n+1,n+1))
new_D[0:n,0:n] = D # copy old matrix into new_D
new_D[-1,:], new_D[:,-1] = d,d # add new row and column
return new_D
def agg_cluster(X):
n = X.shape[0]
sizes = np.ones(n)
D = cdist(X, X,metric = 'sqeuclidean') # initialize distance matr.
np.fill_diagonal(D, np.inf * np.ones(D.shape[0]))
Z = np.zeros((n-1,4)) #linkage matrix encodes hierachy tree
for t in range(n-1):
i,j = np.unravel_index(D.argmin(), D.shape) # minimizer pair
sizes = np.append(sizes, sizes[i] + sizes[j])
Z[t,:]=np.array([i, j, np.sqrt(D[i,j]), sizes[-1]])
D = update_distances(D, i,j, sizes) # update distance matr.
return Z
# MAIN ROUTINE
import scipy.cluster.hierarchy as h
#X = np.genfromtxt('clusterdata.csv',delimiter=',') # read the data
Z = agg_cluster(Xmat) # form the linkage matrix
h.dendrogram(Z) # SciPy can produce a dendogram from Z
# fcluster function assigns cluster ids to all points based on Z
cl = h.fcluster(Z, criterion = 'maxclust', t=3)
import matplotlib.pyplot as plt
plt.figure(2), plt.clf()
cols = ['red','green','blue']
colors = [cols[i-1] for i in cl]
plt.scatter(Xmat[:,0], Xmat[:,1],c=colors)
plt.show()
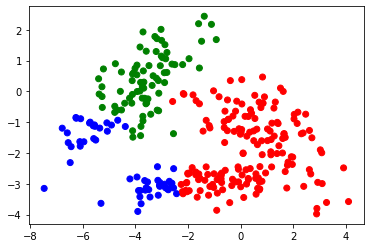
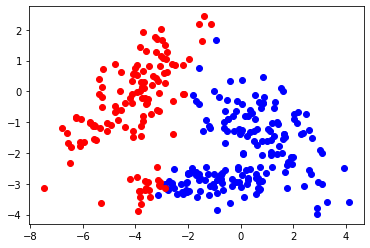
5.4.2. Divisive Hierarchical Clustering#
and now, for the same data, we aply a divisive clustering approach (also taken from [1])
""" clustCE2.py """
import numpy as np
from numpy import genfromtxt
from scipy.spatial.distance import squareform
from scipy.spatial.distance import pdist
import matplotlib.pyplot as plt
def S(x,D):
V1 = np.where(x==0)[0] # {V1,V2} is the partition
V2 = np.where(x==1)[0]
tmp = D[V1]
tmp = tmp[:,V2]
return np.mean(tmp) # the size of the cut
def maxcut(D,N,eps,rho,alpha):
n = D.shape[1]
Ne = int(rho*N)
p = 1/2*np.ones(n)
p[0] = 1.0
while (np.max(np.minimum(p,np.subtract(1,p))) > eps):
x = np.array(np.random.uniform(0,1, (N,n))<=p, dtype=np.int64)
sx = np.zeros(N)
for i in range(N):
sx[i] = S(x[i],D)
sortSX = np.flip(np.argsort(sx))
elIds = sortSX[0:Ne]
elites = x[elIds]
pnew = np.mean(elites, axis=0)
p = alpha*pnew + (1.0-alpha)*p
return np.round(p)
#Xmat = genfromtxt('clusterdata.csv', delimiter=',')
n = Xmat.shape[0]
D = squareform(pdist(Xmat))
N = 1000
eps = 10**-2
rho = 0.1
alpha = 0.9
# CE
pout = maxcut(D,N,eps,rho, alpha);
cutval = S(pout,D)
print("cutvalue ",cutval)
#plot
V1 = np.where(pout==0)[0]
xblue = Xmat[V1]
V2 = np.where(pout==1)[0]
xred = Xmat[V2]
plt.scatter(xblue[:,0],xblue[:,1], c="blue")
plt.scatter(xred[:,0],xred[:,1], c="red")
cutvalue 4.89440804758133
<matplotlib.collections.PathCollection at 0x7fa96b147880>
We will apply HCA to the famous Iris dataset by Fisher. we start by retrieving the data
import requests, zipfile, io
url = "https://archive.ics.uci.edu/static/public/53/iris.zip"
filename = "datasets/iris.data"
r = requests.get(url)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall("datasets")
# from iris.names
# 1. sepal length in cm
# 2. sepal width in cm
# 3. petal length in cm
# 4. petal width in cm
# 5. class
import pandas as pd
df = pd.read_csv(filename, sep=',',header=None, names=['Sepal.length', 'Sepal.width', 'Petal.length','Petal.width','Species'])
df
| Sepal.length | Sepal.width | Petal.length | Petal.width | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
150 rows × 5 columns
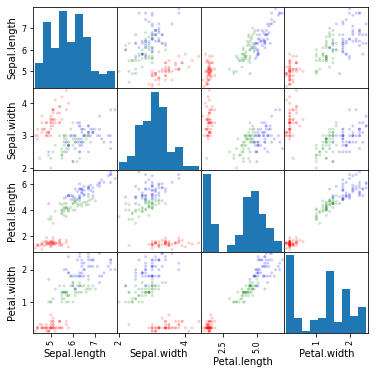
now we build a Scatter Plot Matrix
from pandas.plotting import scatter_matrix
import numpy as np
colors= np.array(50*['r']+50*['g']+50*['b'])
scatter_matrix(df,alpha=0.2,figsize=(6,6),grid=True,diagonal='hist',color=colors)
array([[<AxesSubplot:xlabel='Sepal.length', ylabel='Sepal.length'>,
<AxesSubplot:xlabel='Sepal.width', ylabel='Sepal.length'>,
<AxesSubplot:xlabel='Petal.length', ylabel='Sepal.length'>,
<AxesSubplot:xlabel='Petal.width', ylabel='Sepal.length'>],
[<AxesSubplot:xlabel='Sepal.length', ylabel='Sepal.width'>,
<AxesSubplot:xlabel='Sepal.width', ylabel='Sepal.width'>,
<AxesSubplot:xlabel='Petal.length', ylabel='Sepal.width'>,
<AxesSubplot:xlabel='Petal.width', ylabel='Sepal.width'>],
[<AxesSubplot:xlabel='Sepal.length', ylabel='Petal.length'>,
<AxesSubplot:xlabel='Sepal.width', ylabel='Petal.length'>,
<AxesSubplot:xlabel='Petal.length', ylabel='Petal.length'>,
<AxesSubplot:xlabel='Petal.width', ylabel='Petal.length'>],
[<AxesSubplot:xlabel='Sepal.length', ylabel='Petal.width'>,
<AxesSubplot:xlabel='Sepal.width', ylabel='Petal.width'>,
<AxesSubplot:xlabel='Petal.length', ylabel='Petal.width'>,
<AxesSubplot:xlabel='Petal.width', ylabel='Petal.width'>]],
dtype=object)
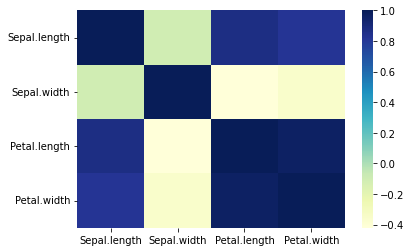
which, in terms of numerical correlation, yields
matrix=df.corr()
print(matrix)
Sepal.length Sepal.width Petal.length Petal.width
Sepal.length 1.000000 -0.109369 0.871754 0.817954
Sepal.width -0.109369 1.000000 -0.420516 -0.356544
Petal.length 0.871754 -0.420516 1.000000 0.962757
Petal.width 0.817954 -0.356544 0.962757 1.000000
which can be visualized easily with a heatmap with seaborn:
import seaborn as sns
sns.heatmap(matrix,cmap='YlGnBu')
<AxesSubplot:>
we can also see the diversity of the data using a Parallel Coordinates plot
plt.figure(figsize=(16,8))
pd.plotting.parallel_coordinates(df,'Species')
<AxesSubplot:>
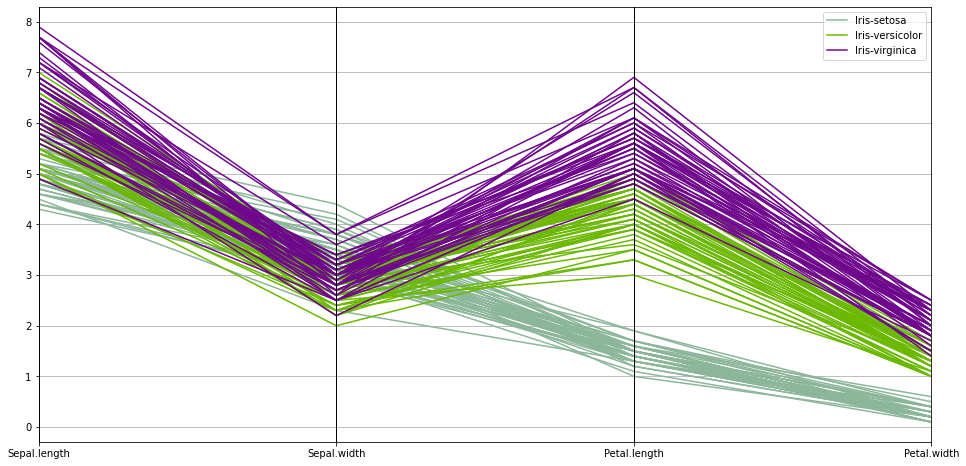
from scipy.cluster.hierarchy import dendrogram, linkage
df_dend = df.set_index('Species')
df_dend = df_dend.reset_index(drop=True)
df.head()
Z = linkage(df_dend,'ward')
plt.figure(figsize=(16,8))
plt.title('Hierarchical clustering dendrogram')
plt.ylabel('sample index')
plt.xlabel('distance (Ward)')
dendrogram(Z,labels=df_dend.index,orientation='left')
plt.show()
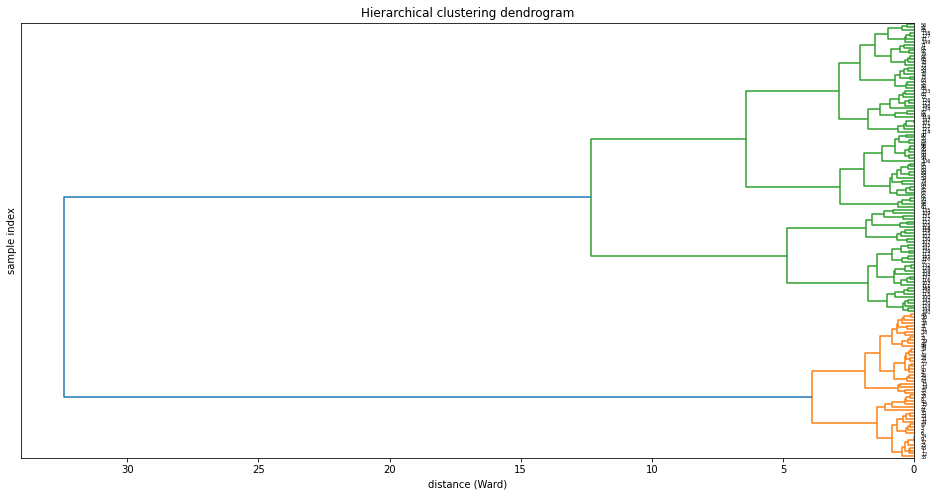
These visualizations easily demonstrat how the separation of the hierarchical clustering is very good with the “Setosa” species, but misses in labeling many “Versicolor” species as “Virginica”. Using again seaborn we can mix the HCA with a heatmap:
sns.clustermap(df_dend)
<seaborn.matrix.ClusterGrid at 0x7fa9629c85b0>
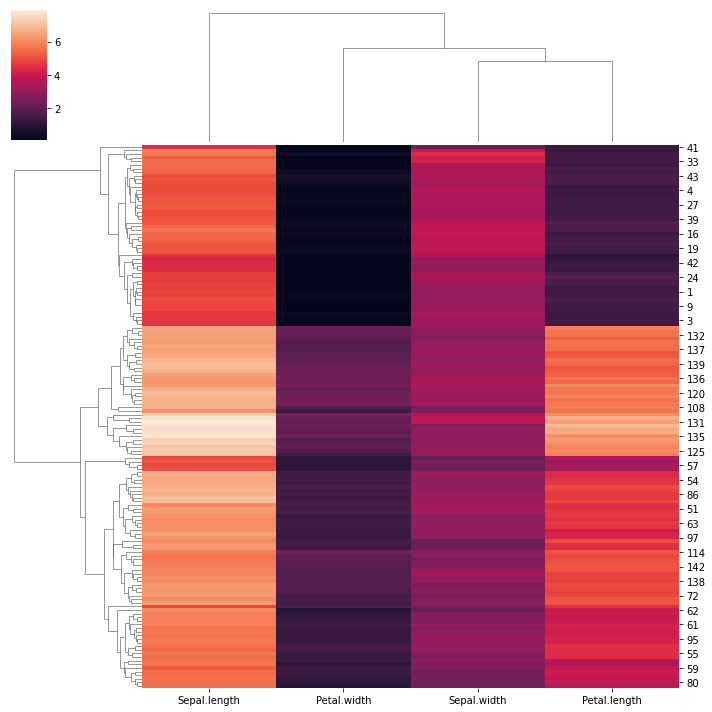
Other hierarchical clustering methods are more popular, like DBSCAN. DBSCAN works well when seeking areas in the data that have a high density of observations, versus areas of the data that are not very dense with observations. DBSCAN can sort data into clusters of varying shapes as well, another strong advantage.
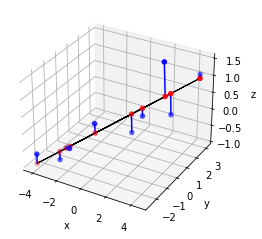
5.5. PCA with Singular Value Decomposition#
""" PCAdat.py """
import numpy as np
X = np.genfromtxt('datasets/pcadat.csv', delimiter=',')
n = X.shape[0]
# Gram matrix
X = X - X.mean(axis=0)
G = X.T @ X
U, _ , _ = np.linalg.svd(G/n)
# projected points first component
Y = X @ np.outer(U[:,0],U[:,0])
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.w_xaxis.set_pane_color((0, 0, 0, 0))
ax.plot(Y[:,0], Y[:,1], Y[:,2], c='k', linewidth=1)
ax.scatter(X[:,0], X[:,1], X[:,2], c='b')
ax.scatter(Y[:,0], Y[:,1], Y[:,2], c='r')
for i in range(n):
ax.plot([X[i,0], Y[i,0]], [X[i,1],Y[i,1]], [X[i,2],Y[i,2]], 'b')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
# %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
plt.savefig('../figures/pca1py.pdf')
plt.show()
# %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Dirk P. Kroese, Zdravko Botev, Thomas Taimre, and Radislav: Vaisman. Data Science and Machine Learning: Mathematical and Statistical Methods. Machine Learning & Pattern Recognition. Chapman & Hall/CRC, 2020. URL: https://acems.org.au/data-science-machine-learning-book-available-download (visited on 2023-08-15).